NEBNext® Multiplex Oligos for Illumina® (96 Unique Dual Index Primer Pairs)
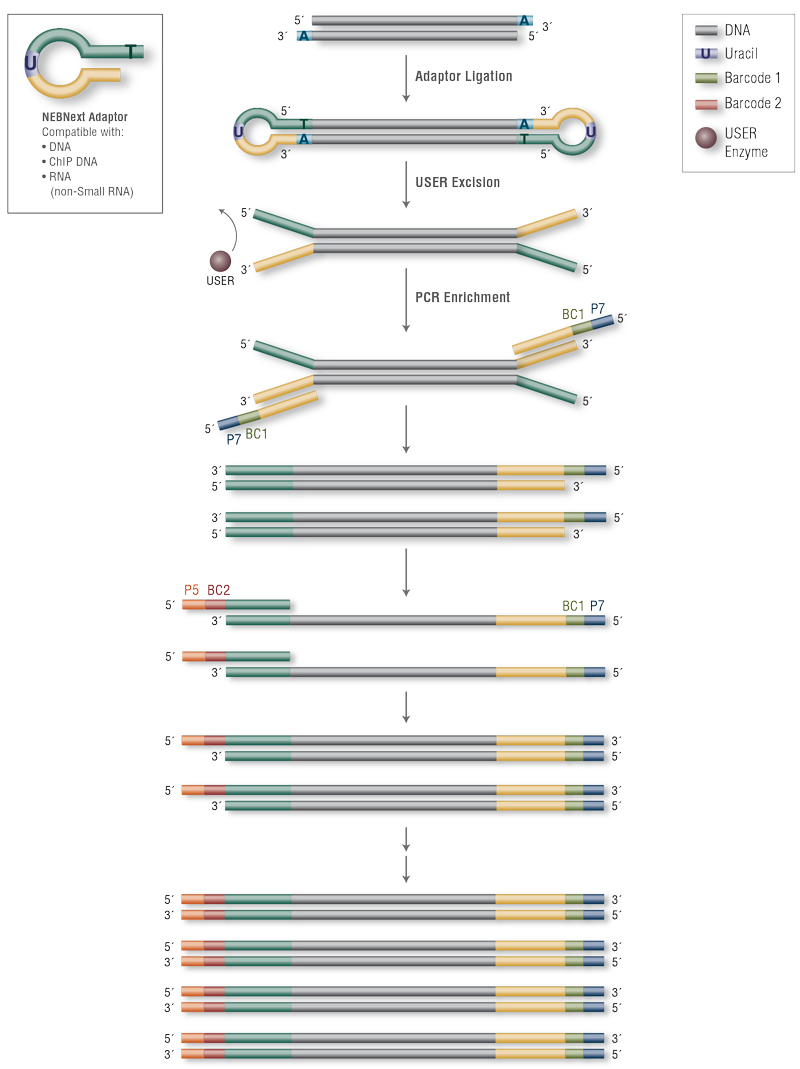
NEBNext® Multiplex Oligos provide adaptors and primers to enable high yield multiplex Illumina® library production. The unique hairpin loop structure of the NEBNext Adaptor minimizes adaptor-dimer formation, and NEBNext index PCR primers enable index incorporation during library amplification. This first set of UDI primer pairs (Set 1 of 5) includes 96 pre-mixed unique pairs of i5 and i7 index primers, packaged in a single-use 96-well plate with a pierceable foil seal.
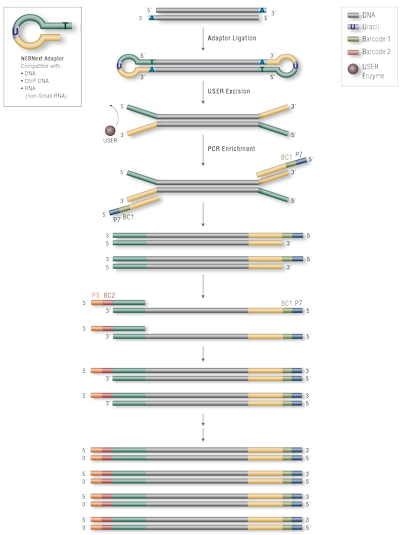
NEBNext® Adaptor ligates with increased efficiency to end-repaired, dA-tailed DNA, due to its novel hairpin-loop structure. The loop includes a uracil (U), which is removed by treatment with USER® Enzyme (a mix of UDG and Endo VIII), opening the loop and making it available as a substrate for PCR. During PCR, NEBNext index primers can be incorporated, thereby enabling multiplexing. This kit includes 96 pre-mixed unique pairs of i5 and i7 index primers, packaged in a single-use 96-well plate with a pierceable foil seal.
NEBNext Oligos are for use with NEBNext products or other standard Illumina-compatible library preparation protocols. Additional options are available in unique dual barcodes (NEB #E6440), dual barcode sets (NEB #E7600, NEB #E7780), single primer sets (in 12- and 96- index formats; NEB #E7335, NEB #E7500, NEB #E7710, NEB #E7730, NEB #E6609), and an option compatible with EM-seq™ and bisulfite sequencing (NEB #E7140).
Workflow:
NEBNext Adaptors enable high-efficiency adaptor ligation and high library yields, with minimized adaptor-dimer formation, and are designed for use in library prep for DNA, ChIP DNA and RNA (but not Small RNA). A novel hairpin loop structure ligates with increased efficiency to end-repaired, dA-tailed DNA. The loop contains a U, which is removed by USER Enzyme (a combination of UDG and Endo VIII), thereby becoming a substrate for PCR, when barcodes can be incorporated by use of the NEBNext index primers. The 96 8-base index primer pairs included in this kit are pre-mixed and are packaged in a single-use 96-well plate with a pierceable foil seal.
Figure 1: Workflow demonstrating the use of NEBNext Multiplex Oligos for Illumina (96 Unique Dual Index Primer Pairs)
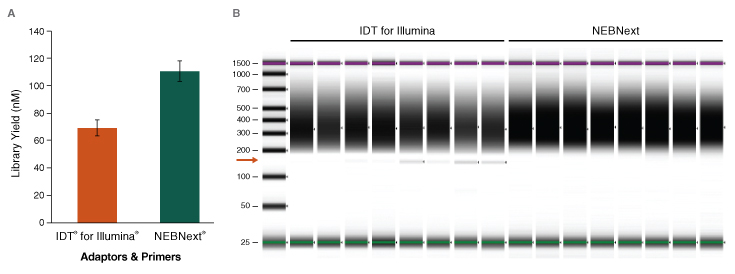
Figure 2: Use of NEBNext Adaptor and Unique Dual Index Primer Pairs substantially increases library yields and minimizes adaptor-dimers
16 libraries were prepared with 100 ng of Human NA19240 genomic DNA (Coriell Institute), using the NEBNext Ultra II FS DNA library prep kit. Adaptors and primers were from either the IDT® for Illumina® –TruSeq® DNA UD Indexes (Illumina # 20022370), or the NEBNext Multiplex Oligos for Illumina (96 Unique Dual Index Primer Pairs). After 4 PCR cycles, libraries were quantified on an Agilent® TapeStation® 4000. A) Average library yields for the 8 libraries made using each workflow show 60% higher yield when the NEBNext Adaptor and Unique Dual Index Primer Pairs are used. B) TapeStation traces of 16 libraries show the presence of adaptor-dimer (indicated by the orange arrow) with the libraries made using IDT for Illumina adaptors and primers, which is absent in the libraries prepared using NEBNext adaptors and primers, which also have higher yields.
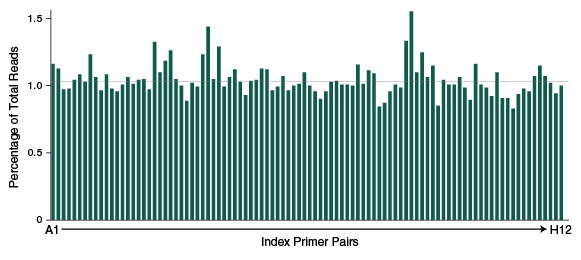
Figure 3: Libraries amplified with NEBNext 96 Unique Dual Index Primer Pairs cluster evenly on the Illumina® NovaSeq™ 6000
96 libraries produced using the NEBNext Ultra II FS DNA library prep kit (Figure 1) and the NEBNext 96 Unique Dual Index Primer Pairs were pooled at equimolar concentrations and sequenced on the Illumina NovaSeq 6000 instrument (2 x 150 bp). The total number of reads from all libraries were summed, and the fraction of the total reads contributed by each library was determined (expected fraction per library=1.04%). All 96 libraries clustered efficiently and were represented at approximately the expected frequency.
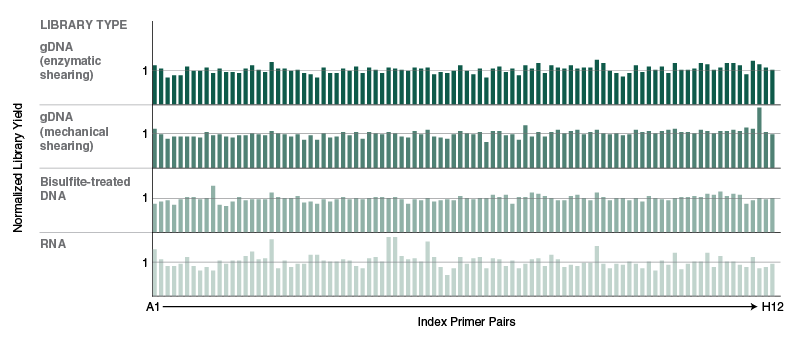
Figure 4: NEBNext 96 Unique Dual Index Primer Pairs amplify libraries with equal efficiency
Human NA19240 genomic DNA (Coriell Institute) was used to prepare 96 libraries using either the NEBNext Ultra II FS DNA library prep kit, Covaris-sheared DNA with the NEBNext Ultra II DNA library prep kit, the Ultra II DNA library prep kit combined with bisulfite conversion, or the NEBNext Ultra II Directional RNA library prep kit. Libraries were PCR-amplified using the NEBNext 96 Unique Dual Index Primer Pairs to produce libraries containing unique i5 and i7 indices. Library yields were quantified (Agilent® TapeStation® 4200) and normalized by summing the total yield of all 96 libraries and calculating the contribution from each library (expected fraction per library = 1.04%). Library amplification efficiency was robust with each library prep method and efficiency was uniform across all 96 unique index primer combinations. Each bar represents the average of at least 2 technical replicates.
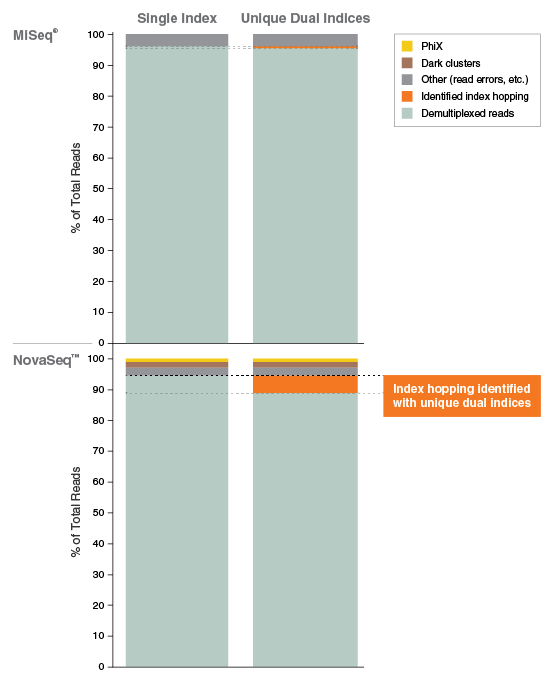
Figure 5: Unique Dual Index Primer Pairs allow identification and discarding of index-hopped reads.
One set of the 96 NEBNext Ultra II FS DNA libraries (Figure 2) was used to assess the accuracy of read classification and filtering of barcode-hopped reads using unique dual indices. The 96 libraries were pooled at equimolar concentration and the pool was sequenced on both the NovaSeq 6000 (2x150 bp) and MiSeq® (2 x 76 bp) instruments. Reads were demultiplexed using the Picard ExtractIlluminaBarcodes tools considering both indices, and classified into the following categories:
Demultiplexed reads: expected i5 and i7 barcode combination
Identified index hopping: expected barcodes, but not in expected combination
Dark clusters: N or G reads (not observed on MiSeq due to 4-color chemistry)
Phi X: any reads matching the universal primer sequence (not present in MiSeq experiment)
Other: any remaining reads not fitting into the above categories
Demultiplexing with a single i5 or i7 index (or a non-unique combination of i5 and i7) incorrectly assigns ~5% of reads on the NovaSeq and 0.6% of reads on the MiSeq, leading to misassignment of reads between samples and problems for downstream analyses. Unique dual indices successfully identify and enable rejection of reads of unknown provenance during demultiplexing.
Figure 6: Libraries amplified with 384 primer pairs from NEBNext Multiplex Oligos for Illumina (96 Unique Dual Index Primer Pairs Set 1-4) cluster evenly on the Illumina NovaSeq™ 6000
384 libraries produced using the NEBNext Ultra II DNA Library Prep Kit (NEB #E7645) and the NEBNext Multiplex Oligos for Illumina (96 Unique Dual Index Primer Pairs Set 1-4) were pooled at equimolar concentrations and sequenced on the Illumina NovaSeq® 6000 instrument. The total number of reads from all libraries were summed, and the fraction of the total reads contributed by each library was determined (expected fraction per library = 0.26 %). All 384 libraries clustered efficiently and were represented at approximately the expected frequency.
This product is related to the following categories:
Use this tool to find citations related to NEBNext products. Search by product, keyword or instrument name – use the filters to select specific product areas.
Additional Citations
Butler, D.J. et al. (2020) Shotgun transcriptome and isothermal profiling of SARS-CoV-2 infection reveals unique host responses, viral diversification, and drug interactions bioRxiv; DOI: https://doi.org/10.1101/2020.04.20.048066
Quality, Safety & Legal
Quality Control Assays
Quality Control tests are performed on each new lot of NEB product to meet the specifications designated for it. Specifications and individual lot data from the tests that are performed for this particular product can be found and downloaded on the Product Specification Sheet, Certificate of Analysis, data card or product manual. Further information regarding NEB product quality can be found here.
Specifications & Change Notifications
The Specification sheet is a document that includes the storage temperature, shelf life and the specifications designated for the product. The following file naming structure is used to name these document files: [Product Number]_[Size]_[Version]
The Certificate of Analysis (COA) is a signed document that includes the storage temperature, expiration date and quality controls for an individual lot. The following file naming structure is used to name these document files: [Product Number]_[Size]_[Version]_[Lot Number]
Products and content are covered by one or more patents, trademarks and/or copyrights owned or controlled by New England Biolabs, Inc (NEB). The use of trademark symbols does not necessarily indicate that the name is trademarked in the country where it is being read; it indicates where the content was originally developed. The use of this product may require the buyer to obtain additional third-party intellectual property rights for certain applications. For more information, please email busdev@neb.com.
This product is intended for research purposes only. This product is not intended to be used for therapeutic or diagnostic purposes in humans or animals.
New England Biolabs (NEB) is committed to practicing ethical science – we believe it is our job as researchers to ask the important questions that when answered will help preserve our quality of life and the world that we live in. However, this research should always be done in safe and ethical manner. Learn more.
Based on your Freezer Program type, you are trying to add a product to your cart that is either not allowed or not allowed with the existing contents of your cart. Please review and update your order accordingly If you have any questions, please contact Customer Service at freezers@neb.com or 1-800-632-5227 x 8.
Help us celebrate our 50th anniversary! We have hidden 1,000 golden butterflies and are waiting for you to find them. They can be anywhere that you find NEB! Beginning April 15th, be sure to visit our website and tables at tradeshows and events you are attending. Visit our social media channels frequently for tips on where we have hidden the butterflies – and once you find one, either click or scan the code to be eligible for a 50th anniversary prize pack, as well as a grand prize trip to NEB headquarters in Ipswich, MA!.
You have been idle for more than 20 minutes, for your security you have been logged out. Please sign back in to continue your session.
Institution Changed
Your profile has been mapped to an Institution, please sign back for your profile updates to be completed.
Sign in to your NEB account
To save your cart and view previous orders, sign in to your NEB account. Adding products to your cart without being signed in will result in a loss of your cart when you do sign in or leave the site.